목차
- 하둡이란 무엇인가?
- 하둡 분산 파일 시스템(HDFS)의 구조와 특징
- 맵리듀스(MapReduce)의 이해
- 하둡 에코시스템 구성 요소
- 자주 출제되는 문제 유형과 해설
- 최종 정리 및 요약
1. 하둡이란 무엇인가?
하둡(Hadoop)은 대용량 데이터를 분산 처리할 수 있는 오픈소스 프레임워크입니다. 구글의 분산 파일 시스템(GFS)과 맵리듀스(MapReduce) 논문에 영감을 받아 아파치 재단에서 개발되었습니다.
하둡의 핵심 구성 요소
- HDFS(Hadoop Distributed File System): 대용량 데이터를 분산 저장하기 위한 파일 시스템
- MapReduce: 분산 처리를 위한 프로그래밍 모델
- YARN(Yet Another Resource Negotiator): 클러스터 자원 관리 및 작업 스케줄링 담당
- Hadoop Common: 하둡의 다른 모듈을 지원하는 공통 유틸리티
하둡은 값비싼 장비 없이도 일반 컴퓨터 여러 대를 클러스터로 연결하여 대용량 데이터를 효율적으로 처리할 수 있게 해주는 기술입니다.
2. 하둡 분산 파일 시스템(HDFS)의 구조와 특징
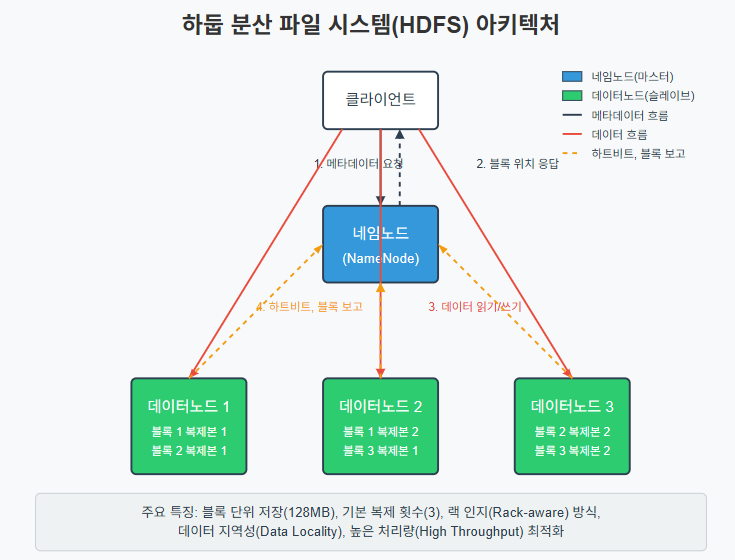
HDFS의 기본 구조
HDFS는 마스터-슬레이브 아키텍처를 기반으로 합니다:
1. 네임노드(NameNode): 마스터 역할
- 파일 시스템의 메타데이터 관리
- 클라이언트의 요청 처리
- 데이터노드 모니터링
2. 데이터노드 (DataNode): 슬레이브 역할
- 실제 데이터 블록 저장
- 데이터 읽기/쓰기 작업 수행
- 주기적으로 네임노드에 상태 보고(하트비트)
HDFS의 주요 특징
1. 블록 단위 저장
- 기본 블록 크기: 128MB (하둡 2.x 이상), 64MB (하둡 1.x)
- 블록 크기는 설정을 통해 변경 가능
- 파일이 블록보다 작으면 실제 크기만큼만 공간 차지
2. 데이터 복제
기본 복제 횟수: 3 (변경 가능)
복제 정책: 랙 인지(Rack-aware) 방식
- 첫 번째 복제본: 로컬 노드
- 두 번째 복제본: 다른 랙의 노드
- 세 번째 복제본: 같은 랙의 다른 노드
복제 설정 방법
-
# hdfs-site.xml 설정 또는 명령어로 변경 가능 hadoop fs -setrep -w 5 /path/to/file
3. 설계 철학
- 한 번 쓰고 여러 번 읽는(Write-once-read-many) 패턴에 최적화
- 높은 처리량(High throughput) 중시, 낮은 지연 시간은 보장하지 않음
- 하드웨어 장애를 일반적인 상황으로 간주
- 데이터 지역성(Data Locality) 활용으로 네트워크 병목 최소화
4. 제약사항
- 실시간 데이터 처리에 부적합
- 작은 파일 많이 저장 시 비효율적 (네임노드 메모리 부담)
- 파일 수정 불가 (덮어쓰기나 추가만 가능)
3. 맵리듀스(MapReduce)의 이해
맵리듀스는 대용량 데이터를 병렬로 처리하기 위한 프로그래밍 모델입니다.
맵리듀스 처리 과정
1. 맵(Map) 단계
- 입력 데이터를 키-값 쌍으로 변환하여 처리
- 각 맵 태스크는 독립적으로 실행됨
2. 셔플(Shuffle)과 정렬(Sort) 단계
- 맵 단계의 출력을 키별로 그룹화
- 같은 키를 가진 값들이 같은 리듀서로 전달됨
3. 리듀스(Reduce) 단계
- 그룹화된 데이터에 집계 연산 수행
- 최종 결과 생성
맵리듀스 처리 흐름 도식

맵리듀스 특징
- 데이터 지역성(Data Locality) 활용: 데이터가 있는 곳으로 코드 이동
- 장애 허용(Fault Tolerance): 태스크 실패 시 자동 재시도
- 확장성(Scalability): 노드 추가로 처리 능력 선형적 확장
- 단순한 프로그래밍 모델: 맵과 리듀스 함수만 구현하면 됨
4. 하둡 에코시스템 구성 요소
하둡 주변에는 다양한 관련 프로젝트들이 존재하며, 이를 하둡 에코시스템이라고 합니다.
주요 구성 요소와 역할
| 구성요소 | 주요 역할 및 특징 |
| HDFS | 대용량 파일을 분산 저장하기 위한 파일 시스템 |
| MapReduce | 분산 처리를 위한 프로그래밍 모델 |
| YARN | 클러스터 자원 관리 및 작업 스케줄링 담당 |
| Hive | SQL 유사 언어(HiveQL)로 하둡 데이터 쿼리 및 분석 |
| Pig | 데이터 플로우 언어 및 실행 환경 |
| HBase | 컬럼 기반 NoSQL 데이터베이스, 실시간 랜덤 접근 제공 |
| Sqoop | 관계형 DB와 하둡 간 데이터 전송 도구 |
| Flume | 로그 데이터 수집 및 집계 도구 |
| ZooKeeper | 분산 코디네이션 서비스 |
| Oozie | 워크플로우 관리 및 스케줄링 |
| Spark | 인메모리 기반 고속 데이터 처리 엔진 |
5. 자주 출제되는 문제 유형과 해설
문제 유형 1: HDFS 구조와 특징
다음 중 하둡 분산 파일 시스템(HDFS)에 대한 설명으로 옳은 것은?
1. 복제 횟수는 내부에서 결정되며 사용자가 임의로 변경할 수 없다.
2. EXT4, NTFS가 상위 시스템이다.
3. GFS와 동일한 소스코드를 사용한다.
4. 네임노드와 데이터노드의 개수는 항상 동일하다.
해설
모든 보기가 틀린 설명입니다.
- 복제 횟수는 기본값이 3이지만, 사용자가 변경할 수 있습니다.
- EXT4와 NTFS는 로컬 파일 시스템이며, HDFS와 상하위 관계가 아닙니다.
- HDFS는 GFS에서 영감을 받았지만 완전히 다른 소스코드로 구현되었습니다.
- 네임노드는 일반적으로 1~2개이고, 데이터노드는 수십~수백 개로 구성됩니다.
문제 유형 2: 네임노드와 데이터노드 역할
하둡 분산 파일 시스템(HDFS)의 네임노드(NameNode)와 데이터노드(DataNode)에 대한 설명으로 옳은 것은?
1. 네임노드는 블록 데이터를 직접 저장한다.
2. 데이터노드는 파일 시스템의 네임스페이스를 관리한다.
3. 네임노드와 데이터노드는 1:1로 매핑된다.
4. 네임노드는 메모리에 파일 시스템의 메타데이터를 유지한다.
해설
4번이 옳습니다. 네임노드는 파일 시스템의 메타데이터(파일 이름, 권한, 위치, 블록 정보 등)를 메모리에 유지합니다. 반면, 실제 데이터 블록은 데이터노드에 저장됩니다. 네임노드와 데이터노드는 1:N 관계이며, 데이터노드는 네임노드에 주기적으로 하트비트와 블록 보고를 전송합니다.
문제 유형 3 (HDFS 블록과 복제)
하둡 분산 파일 시스템(HDFS)의 블록에 대한 설명으로 옳은 것은?
1. 기본 블록 크기는 4KB이다.
2. 모든 파일은 블록 크기와 정확히 일치하도록 저장된다.
3. 블록 크기는 한 번 설정되면 변경할 수 없다.
4. 파일은 블록 단위로 분할되어 여러 데이터노드에 분산 저장될 수 있다.
해설
4번이 옳습니다. HDFS에서 파일은 블록 단위로 분할되어 여러 데이터노드에 분산 저장됩니다. 기본 블록 크기는 128MB(하둡 2.x) 또는 64MB(하둡 1.x)이며, 파일이 블록보다 작으면 실제 크기만큼만 공간을 차지합니다. 블록 크기는 설정을 통해 변경 가능합니다.
문제 유형 4 (맵리듀스 처리 과정)
하둡의 맵리듀스(MapReduce) 프레임워크에 대한 설명으로 옳지 않은 것은?
1. 맵(Map) 단계에서는 입력 데이터를 키-값 쌍으로 변환한다.
2. 리듀스(Reduce) 단계 전에 셔플(Shuffle)과 정렬(Sort) 과정이 수행된다.
3. 맵 태스크와 리듀스 태스크는 항상 1:1로 매핑된다.
4. 맵리듀스 작업은 YARN을 통해 리소스 관리 및 스케줄링된다.
해설
3번이 옳지 않습니다. 맵 태스크와 리듀스 태스크는 1:1로 매핑되지 않으며, 일반적으로 여러 맵 태스크의 결과가 하나의 리듀스 태스크로 전달됩니다. 리듀스 태스크의 수는 개발자가 설정할 수 있으며, 리듀스 태스크 없이 맵 태스크만 수행하는 것도 가능합니다.
문제 유형 5 (하둡 에코시스템)
다음 중 하둡 에코시스템의 구성요소와 그 역할이 올바르게 연결된 것은?
1. Flume - 워크플로우 관리 및 스케줄링
2. Pig - 분산 데이터베이스 시스템
3. Hive - 대용량 데이터의 SQL 기반 처리
4. Sqoop - 실시간 스트리밍 처리
해설
3번이 옳습니다. Hive는 SQL 유사 언어인 HiveQL을 사용하여 하둡 상의 데이터를 쿼리하고 분석할 수 있는 데이터 웨어하우스 인프라입니다. 정확한 역할은 다음과 같습니다.
- Flume: 로그 수집 도구
- Pig: 데이터 플로우 언어 및 실행 환경
- Sqoop: 관계형 데이터베이스와 하둡 간의 데이터 전송 도구
6. 최종 정리 및 요약
HDFS 핵심 개념 정리
- 아키텍처: 네임노드(마스터)와 데이터노드(슬레이브) 구조
- 데이터 저장: 블록 단위(기본 128MB) 분산 저장
- 복제 정책: 기본 3개 복제, 랙 인지(Rack-aware) 방식
- 장점: 대용량 데이터 처리, 내고장성, 높은 처리량
- 한계: 실시간 처리 부적합, 작은 파일 처리 비효율적
맵리듀스 핵심 개념 정리
- 처리 단계: Map → Shuffle & Sort → Reduce
- 특징: 데이터 지역성, 장애 허용, 확장성
- 구현: 맵 함수와 리듀스 함수 구현으로 분산 처리 가능
하둡 에코시스템 핵심 구성 요소
- 데이터 저장 : HDFS, HBase
- 처리 엔진 : MapReduce, Spark
- 데이터 접근 : Hive, Pig
- 데이터 통합 : Sqoop, Flume
- 관리 도구 : YARN, ZooKeeper, Oozie
시험 대비 팁
- 개념 이해 : 각 구성 요소의 역할과 상호작용 이해
- 특징 암기 : 각 기술의 주요 특징과 제약사항 숙지
- 비교 분석 : 유사한 기술 간의 차이점 파악
- 실무 관점 : 어떤 상황에서 어떤 기술을 활용할지 생각
빅데이터분석기사 시험은 단순 암기보다 개념 이해가 중요합니다. 하둡의 기본 원리와 구성 요소들의 역할을 제대로 이해하면, 다양한 형태의 문제에도 유연하게 대응할 수 있을 것입니다.
이 글이 여러분의 빅데이터분석기사 필기 시험 준비에 큰 도움이 되었기를 바랍니다. 화이팅! 🚀
'AI,DT' 카테고리의 다른 글
| 데이터 드리프트(Data Drift) : 머신러닝 모델의 숨은 위협과 대응 전략 (0) | 2025.02.13 |
|---|---|
| 2025년 AI 트렌드 분석 : 기업과 기술의 미래를 바꾸다 (0) | 2025.02.13 |
| AI 시대, 질문력이 곧 경쟁력이 되는 이유 🤔 (7) | 2024.11.03 |
| 정량 데이터와 정성 데이터 : 함께 사용할 때 더 강력한 분석 도구 (0) | 2024.11.02 |
| 《AI 이후의 세계》 리뷰 : 인류는 어떻게 AI와 공존할 것인가? (8) | 2024.10.24 |



